This the third and final article in our series describing the three tiers of a serverless architecture. In the first article we took you on a tour of the first tier—the front end. In the second article, we took a detailed look at the middle tier—the business logic. In this article, we break down the third tier, the serverless back end architecture.
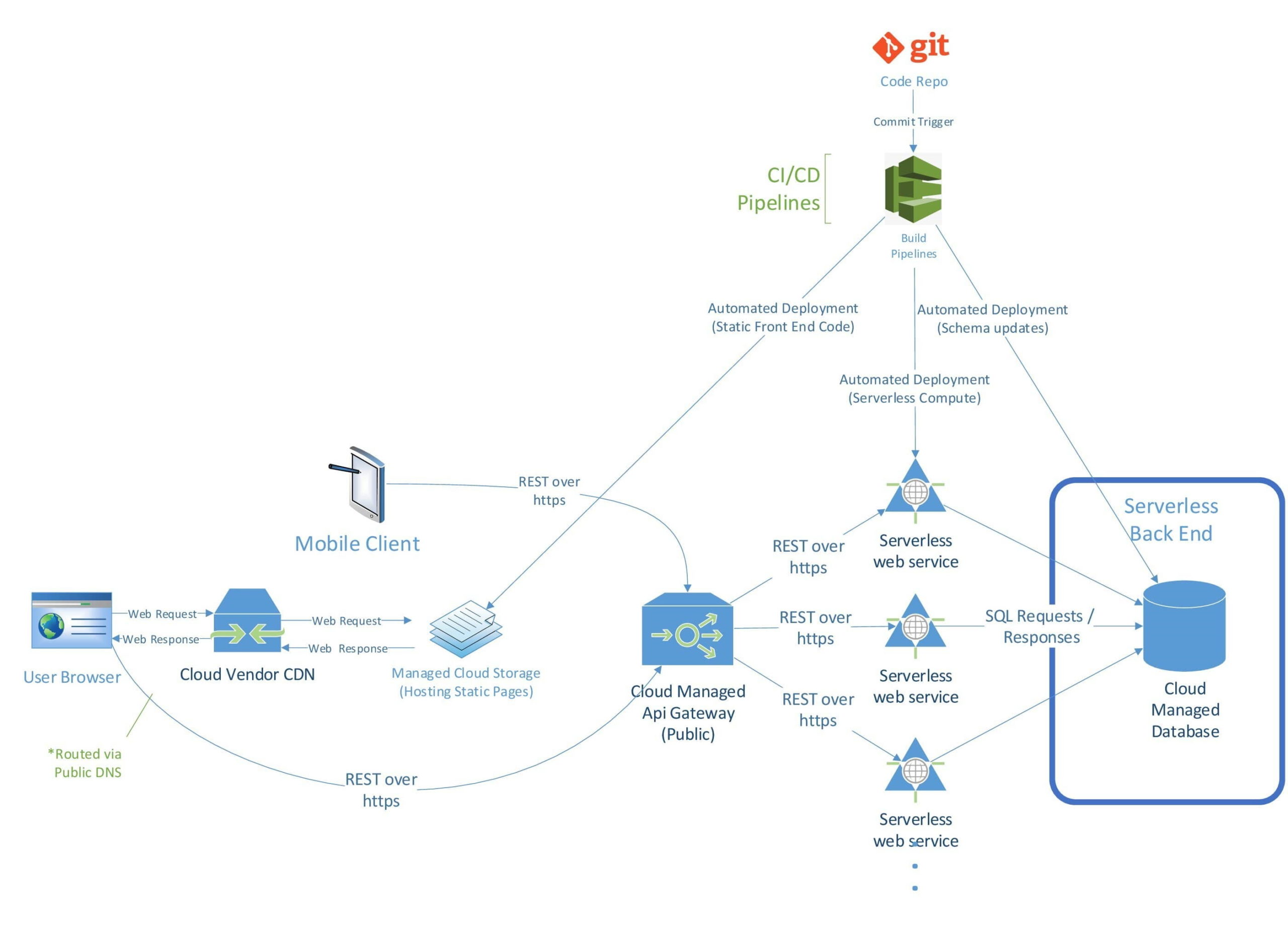
Although the diagram above shows the back end of a serverless architecture as a Cloud-managed database, the back end can, in fact, be much more than just a database. And it differs significantly from the other two tiers of a serverless architecture.
The serverless back end is where all your application data resides. It gives the application the ability to pull in and process data from disparate sources as well as persist its own data. The back end also contains the information that you want to display to users. As with the other two tiers, automated deployment and testing are strongly recommended for the back end. An automation-focused approach to the back end will shorten your software development life cycle (SDLC), reduce your down time, and decrease your bug list.
When you think of the back end, you may think of structured databases such as those that are created with SQL. While these types of databases certainly have a place in the serverless architecture, they are not always the best fit for the job at hand. In the next section we’ll discuss the various types of data management solutions you may want to use for your serverless application.
Serverless Back End Architectures
Cloud vendors support a wide array of datastore architectures, including:
- Traditional SQL servers – all your familiar database technologies are supported in the Cloud, often as serverless managed services provided by the vendor. When a vendor offers a traditional database as a managed service, you no longer need to worry about setting up and testing scaling or failover. The vendor provides this as part of the managed solution.
- NoSQL – Essentially the same as the managed services you get with traditional SQL databases, except that these store data in structured files instead of tables (JSON and MongoDB are examples).
- Data warehouse –These often are large sets of processed historical data used for a specific purpose such as business analytics or data mining and statistical analysis. Data may or may not be stored in tables. The major Cloud vendors such as AWS, Azure, and Google offer managed, turnkey data lakes, but there are also Cloud vendors who specialize in data lakes, either on premise or deployed on top of your favorite Cloud vendor.
- Data Lake – Data lakes are usually a repository for vast amounts of unstructured and unorganized data. This data is most often used by data scientists. Data from a data lake generally flows into a data warehouse once an organization discovers a utility for that data.
Data warehouses and data lakes are usually the most complicated and resource-intensive backend data stores that exist today. The major Cloud vendors provide comparatively cost-effective and powerful solutions for these types of architectures. Part of the reason they are so good at it is that vendors such as AWS and Google have had to figure out how best to manage the vast amounts of data they accumulated early in their existence. They solved the problem for themselves and then productized it for the rest of us. If you need a large, complex data store, it’s usually best to use a Cloud-native solution rather than try to build and maintain it yourself.
What makes these data store architectures serverless is that the Cloud vendor manages the data servers and the operating systems, and the networking infrastructure that supports them. You don’t have to worry about those aspects at all.
Serverless Back End Considerations
Your Cloud vendor has different types of backend data stores to choose from. What type you choose is determined by what you want your application to do. If you have large amounts of processed data you need at your fingertips, you would choose a data warehouse.
If you’re a data scientist with a large amount of raw data that you plan to use, you would choose a data lake. Cloud vendors offer many services that let data scientists work productively with raw data. These include machine learning, artificial intelligence, and analytical tools. These services, in conjunction with the services you are creating with your developers, are what make sense of your data; analysis leads to insights, which leads to change and growth.
Every scenario that you can imagine can technically be hosted by a Cloud vendor or SaaS (such as Cloudera). It’s important to remember that you don’t have to custom-build services to work with your back end. Both Cloud and SaaS vendors have many out-of-the-box services designed to work with a myriad of backend configurations.
You may want to consider a hybrid cloud solution, where your back end is external to the rest of the Cloud-native infrastructure because of the sensitivity of your data. You can still go through a Cloud provider such as Amazon or Google Cloud services, but you will also have a physical server you have to manage yourself.
One argument against storing your data in the cloud has traditionally been the sensitivity of said data. Many organizations have assumed that their customer or business data would be too exposed if it were hosted in the cloud.
Until recently this was often true. Now, Cloud vendors are offering hosting and security solutions that can meet some of the most stringent security requirements. Even HIPAA and government compliant solutions exist in Cloud-based architectures. They can even be managed and serverless. And, in August of 2021, Microsoft Azure announced that top secret data (such as that of the Department of Defense) can be stored in the Cloud using Azure Government Top Secret.
Serverless Architecture Data Security Considerations
Data security is paramount whether you have a hybrid solution or you have a completely Cloud-based solution. You want only a limited number of services to have direct access to your data. So in our example of serverless web application architecture, you need to set up your back end so that the front end is not pulling data directly from the database. Only the internal services in the middle tier of the architecture should have access to the back end. This is accomplished through the API gateways, firewalls, and strict access authorization control (i.e., role-based access control).
If you choose a hybrid solution, you should ensure that a site VPN is set up for Cloud access to your onsite data. You should also have rigid data control policies so your physical database server can’t be breached. A good way to protect your onsite server is to copy specific data sets intended for Cloud use to the Cloud so that your physical server is never accessed.
Examples of Traditional Client/Server Environments That Work Better in a Cloud/Serverless Architecture
Machine Learning
Machine learning is possible in a traditional client/server environment, but it is better to run it in a Cloud/serverless architecture. Machine learning can’t be easily put into a data center because of the size of the data and because of limited bandwidth. This is difficult for you to do by yourself. You want a Software as a Service (SaaS) or Cloud vendor to do it for you instead. Machine learning is much more cost-effective in the Cloud.
Data Analytics
The Cloud is the best place to do analytics on data lakes because Cloud vendors have been doing this for many years as part of their business model. They have developed, as part of their businesses, services and tools that you can use to do in-depth analytics on your data to get the insights you need for your own business or research.
Data Processing/Transformation
Cloud vendors such as Google and Amazon have data processing/transformation down to a science because this, too, is part of their business operations. That makes it the best and most cost-effective place to do data processing and transformation.
Why Should You Consider a Serverless Back End?
If you’re already using serverless architecture, you may be debating whether you want your data to be in a serverless back end or hosted on a physical infrastructure you maintain on site. If you are moving from a traditional client/server environment to a serverless architecture, you may not be sure whether you want a serverless back end.
Here’s why a serverless back end makes sense in both of these scenarios. First, the security risk is lowered when your back end is serverless. That’s because the Cloud vendor manages the server(s) and they keep everything, including security-related bug fixes, completely up to date.
When you have a server on site, you have to depend on your IT team to keep it updated. Although this is the ideal, in the real world, it doesn’t always happen in a timely manner or at all. This puts your onsite data at a higher risk of being breached or compromised.
Another benefit of having a serverless back end is that it is not obvious to outsiders where your data resides. This is because the middle tier is locked down and nothing external to the middle tier ever touches the back end. This is an additional function that keeps your data more secure.
When you have a serverless back end, your Cloud vendor also guarantees high availability—five nines—for your data. Since data is crucial to your application, having this kind of availability is extremely important for you and for your customers.